XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 28 março 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

Results reported on TrecQA, WikiQA, and SQUAD-Sent datasets. SQUAD
The OIG Dataset

Spoken-SQuAD Dataset

How SIGNAL IDUNA operationalizes machine learning projects on AWS
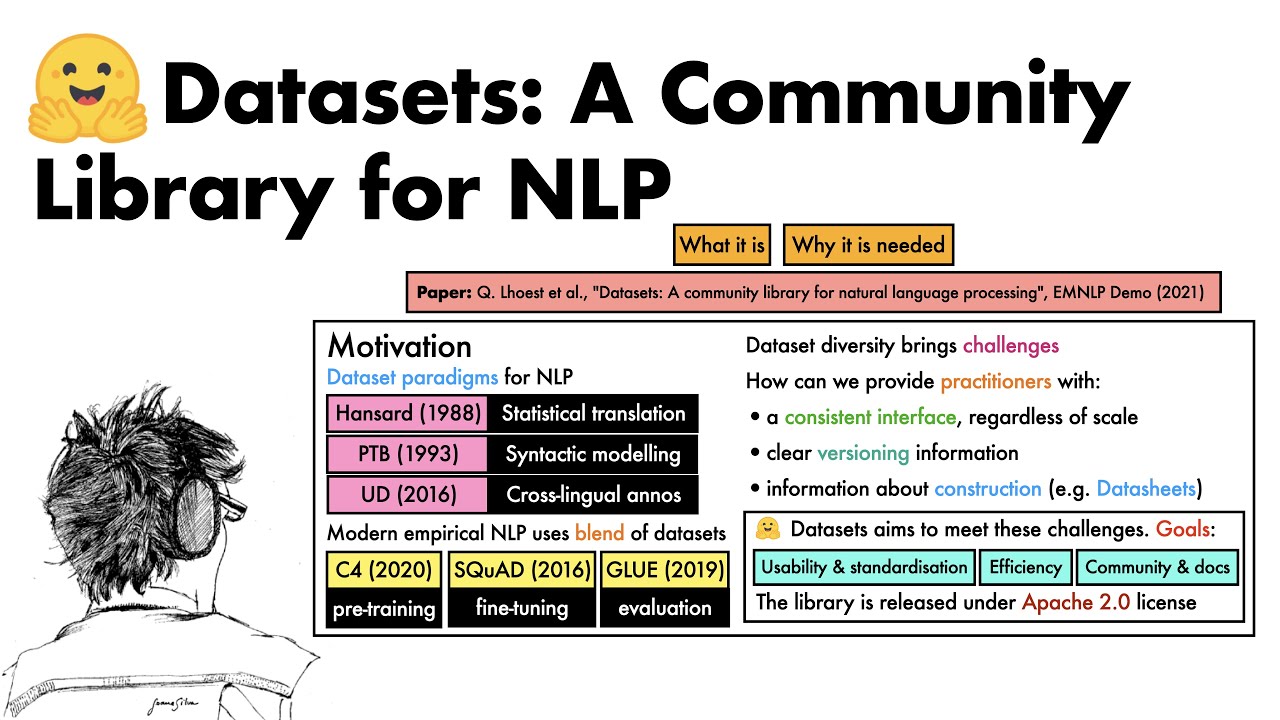
🤗 Datasets: A community library for natural language processing

An example from the SQuAD dataset. Evidences needed for the answer
GitHub - pallavrajsahoo/Question-Answering-System-with-SQuAD
End to End Question-Answering System Using NLP and SQuAD Dataset

Sample from the GermanDPR dataset. 0.0 0.2 0.4 0.6 0.8 1.0 0.4 0.5

Nlakh Dataset Papers With Code

Papers with code or without code? Impact of GitHub repository

XQuAD Benchmark (Cross-Lingual Question Answering)

VCTK Dataset - Machine Learning Datasets
Recomendado para você
-
 Internal Combustion Engines 2013-2014 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download28 março 2025
Internal Combustion Engines 2013-2014 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download28 março 2025 -
I.C. Engine, PDF, Internal Combustion Engine28 março 2025
-
 ASE Diesel Engines test T2 practice test 1 with Answers., Exams Nursing28 março 2025
ASE Diesel Engines test T2 practice test 1 with Answers., Exams Nursing28 março 2025 -
 Petrol Engine MCQ, IC Engine MCQ Questions, Petrol Engine vs Diesel Engine28 março 2025
Petrol Engine MCQ, IC Engine MCQ Questions, Petrol Engine vs Diesel Engine28 março 2025 -
 Ic engine ies gate ias 20 years question and answers28 março 2025
Ic engine ies gate ias 20 years question and answers28 março 2025 -
![IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!](https://storage.googleapis.com/tb-img/production/19/06/RRB_JE_ME_49_15Q_TE_CH_4_HIndi%20-%20Final_Diag%28Shashi%29_images_Q7.PNG) IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!28 março 2025
IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!28 março 2025 -
.jpg) Marine Notes: Lamb's Questions and Answers on Marine Diesel Engine by marinenotes28 março 2025
Marine Notes: Lamb's Questions and Answers on Marine Diesel Engine by marinenotes28 março 2025 -
 Dk & Eng - Engine - Page 1 - Witherbys28 março 2025
Dk & Eng - Engine - Page 1 - Witherbys28 março 2025 -
 Steam Turbine Interview Question Answer Pdf - Colaboratory28 março 2025
Steam Turbine Interview Question Answer Pdf - Colaboratory28 março 2025 -
 Modern Marvels Engines.doc - Name History Channel Film Quiz - Engines 1. What is the root word of engine? 2. The engine ushered in the28 março 2025
Modern Marvels Engines.doc - Name History Channel Film Quiz - Engines 1. What is the root word of engine? 2. The engine ushered in the28 março 2025

você pode gostar
-
 QUIZ DI UWUFUFU TRA SOCIAL E CIBO : r/Sharts28 março 2025
QUIZ DI UWUFUFU TRA SOCIAL E CIBO : r/Sharts28 março 2025 -
 Auto Clicker By Shocker 3.0.1 Download For Windows PC - Softlay28 março 2025
Auto Clicker By Shocker 3.0.1 Download For Windows PC - Softlay28 março 2025 -
format(webp)) Humans Take on the Gods in New Record of Ragnarok TV Anime Visual28 março 2025
Humans Take on the Gods in New Record of Ragnarok TV Anime Visual28 março 2025 -
Bleach Animated World - 🔥 Kurosaki Ichigo 🔥 Bleach TYBW Episode28 março 2025
-
 Star Wars: Episode VIII - The Last Jedi - Fanedit.org28 março 2025
Star Wars: Episode VIII - The Last Jedi - Fanedit.org28 março 2025 -
Demon Slayer- Kimetsu no Yaiba Season 3 - Official Trailer - Vidéo28 março 2025
-
 SUBWAY SURFERS HAVANA 2018!28 março 2025
SUBWAY SURFERS HAVANA 2018!28 março 2025 -
Do you prefer Velma left or right? 🧡🧡 #velma #cosplay28 março 2025
-
Buy Shang Tsung - Kombat Pack Version - Microsoft Store en-IL28 março 2025
-
 Downtown Boston from Renaissance Parking Garage, Pictured B…28 março 2025
Downtown Boston from Renaissance Parking Garage, Pictured B…28 março 2025


