A Neural Parametric Singing Synthesizer – arXiv Vanity
Por um escritor misterioso
Last updated 14 abril 2025

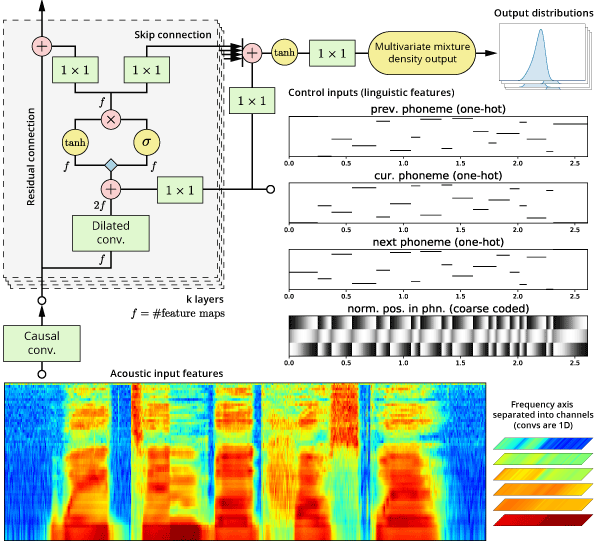
We present a new model for singing synthesis based on a modified version of the WaveNet architecture. Instead of modeling raw waveform, we model features produced by a parametric vocoder that separates the influence of pitch and timbre. This allows conveniently modifying pitch to match any target melody, facilitates training on more modest dataset sizes, and significantly reduces training and generation times. Our model makes frame-wise predictions using mixture density outputs rather than categorical outputs in order to reduce the required parameter count. As we found overfitting to be an issue with the relatively small datasets used in our experiments, we propose a method to regularize the model and make the autoregressive generation process more robust to prediction errors. Using a simple multi-stream architecture, harmonic, aperiodic and voiced/unvoiced components can all be predicted in a coherent manner. We compare our method to existing parametric statistical and state-of-the-art concatenative methods using quantitative metrics and a listening test. While naive implementations of the autoregressive generation algorithm tend to be inefficient, using a smart algorithm we can greatly speed up the process and obtain a system that’s competitive in both speed and quality.

HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis

Singing voice synthesis based on frame-level sequence-to-sequence

Conditioning Deep Generative Raw Audio Models for Structured

2019年5月版] 機械学習・深層学習を学び、トレンドを追うためのリンク

WGANSing: A Multi-Voice Singing Voice Synthesizer Based on the

DiffSinger: Singing Voice Synthesis via Shallow Diffusion
A Neural Parametric Singing Synthesizer

A Survey on Recent Deep Learning-driven Singing Voice Synthesis

Speaker Anonymization Using X-vector and Neural Waveform Models

A Neural Parametric Singing Synthesizer

NU-GAN: High resolution neural upsampling with GAN – arXiv Vanity

Conditioning Deep Generative Raw Audio Models for Structured
Recomendado para você
-
 Original New Leader Power Supply, AC Input: 100-240V~50/60hz 0.5A, DC Output: 12V, 1.5A, RoHS Compliant14 abril 2025
Original New Leader Power Supply, AC Input: 100-240V~50/60hz 0.5A, DC Output: 12V, 1.5A, RoHS Compliant14 abril 2025 -
 universal input 100~240v 50/60hz ac dc14 abril 2025
universal input 100~240v 50/60hz ac dc14 abril 2025 -
 Fonte de Alimentação Arte Sedução Carregador para Cabine14 abril 2025
Fonte de Alimentação Arte Sedução Carregador para Cabine14 abril 2025 -
 input 100-240v ac 50-60hz output 12v14 abril 2025
input 100-240v ac 50-60hz output 12v14 abril 2025 -
 Music in the brain Nature Reviews Neuroscience14 abril 2025
Music in the brain Nature Reviews Neuroscience14 abril 2025 -
 Reviews for BEFREE SOUND 12 in. Rechargeable Double Subwoofer14 abril 2025
Reviews for BEFREE SOUND 12 in. Rechargeable Double Subwoofer14 abril 2025 -
 Singing Machine Karaoke System Classic Series SML385W + Two Microphones, Tested14 abril 2025
Singing Machine Karaoke System Classic Series SML385W + Two Microphones, Tested14 abril 2025 -
 JBL PartyBox 200 Portable Bluetooth party speaker with light effects14 abril 2025
JBL PartyBox 200 Portable Bluetooth party speaker with light effects14 abril 2025 -
 Seasonic G12 GM-850 850W 80 Plus Gold Semi Modular14 abril 2025
Seasonic G12 GM-850 850W 80 Plus Gold Semi Modular14 abril 2025 -
 Build an Interactive Data Visualization with D3.js and Observable14 abril 2025
Build an Interactive Data Visualization with D3.js and Observable14 abril 2025
você pode gostar
-
 Papa Louie 3 - Play Online on SilverGames 🕹️14 abril 2025
Papa Louie 3 - Play Online on SilverGames 🕹️14 abril 2025 -
 É um sonho que se torna realidade: karrigan cai em lágrimas após conquista em Katowice14 abril 2025
É um sonho que se torna realidade: karrigan cai em lágrimas após conquista em Katowice14 abril 2025 -
 Goodbye - Music Video by AVAION & Sam Welch - Apple Music14 abril 2025
Goodbye - Music Video by AVAION & Sam Welch - Apple Music14 abril 2025 -
 Banban x banbaleena garten of banban in 202314 abril 2025
Banban x banbaleena garten of banban in 202314 abril 2025 -
 You've seen Jackbox and Jeffbox, now here comes ROCKBOX! : r14 abril 2025
You've seen Jackbox and Jeffbox, now here comes ROCKBOX! : r14 abril 2025 -
 Desenhando um cavalo14 abril 2025
Desenhando um cavalo14 abril 2025 -
 Where to find Generators and Ventilation in Roblox Forgotten14 abril 2025
Where to find Generators and Ventilation in Roblox Forgotten14 abril 2025 -
 Free Roblox codes (March 2023); all free available promo codes14 abril 2025
Free Roblox codes (March 2023); all free available promo codes14 abril 2025 -
 Stickman War - Free Play & No Download14 abril 2025
Stickman War - Free Play & No Download14 abril 2025 -
 Akane Hououji MBTI Personality Type: ISTP or ISTJ?14 abril 2025
Akane Hououji MBTI Personality Type: ISTP or ISTJ?14 abril 2025