RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 14 abril 2025

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
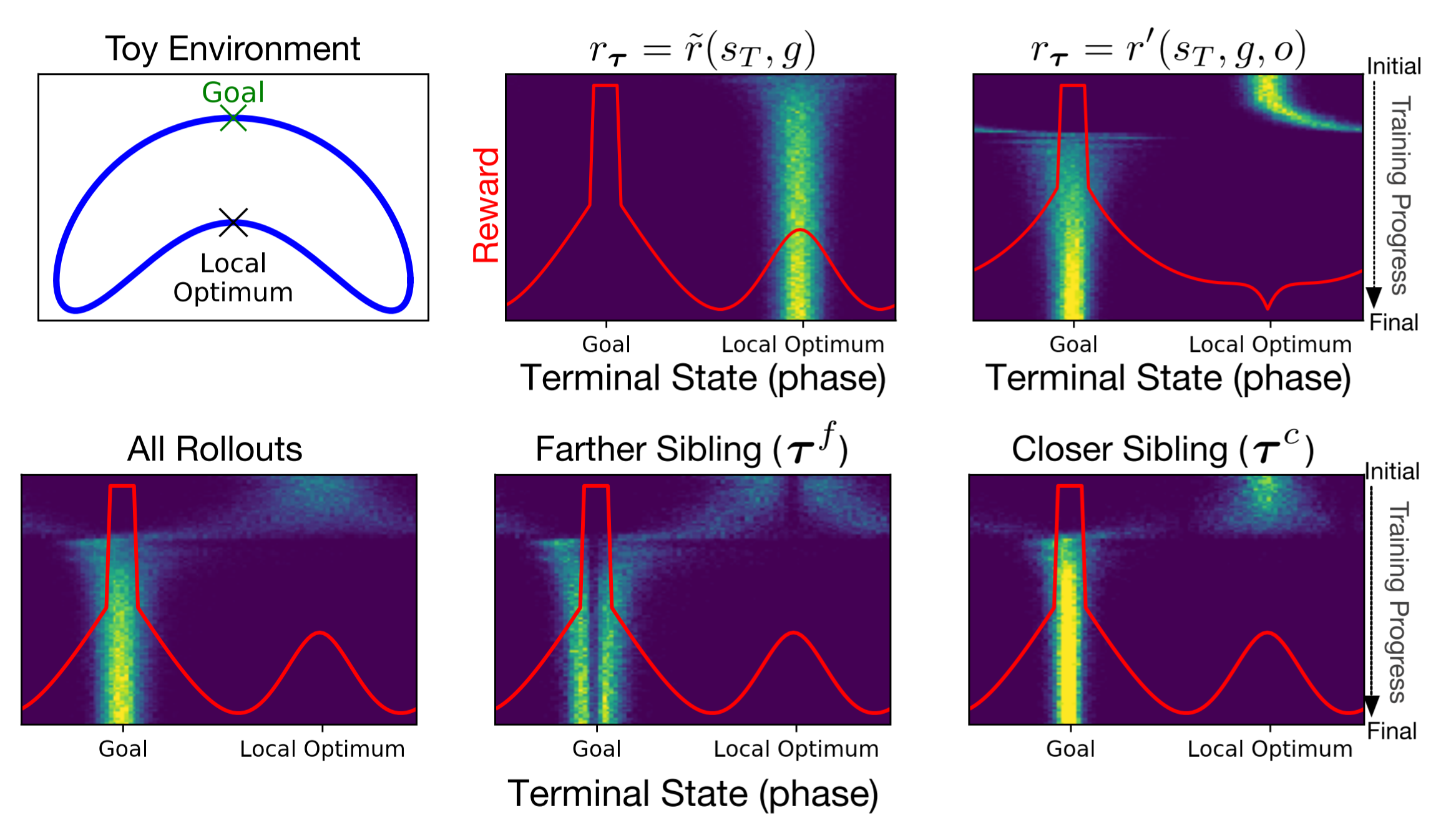
RL Weekly 35: Escaping Local Optimas in Distance-based Rewards and Choosing the Best Teacher

PDF) Model-free Reinforcement Learning with Stochastic Reward Stabilization for Recommender Systems

PDF) Tensor Implementation of Monte-Carlo Tree Search for Model-Based Reinforcement Learning
Applied Sciences, Free Full-Text
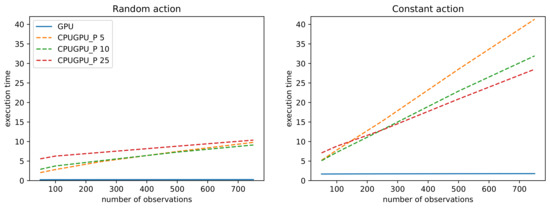
Applied Sciences, Free Full-Text

Uncategorized – Severely Theoretical

Home
RL Weekly
Aman's AI Journal • Papers List
Memory for Lean Reinforcement Learning.pdf
Recomendado para você
-
 Leela Chess Zero: AlphaZero for the PC14 abril 2025
Leela Chess Zero: AlphaZero for the PC14 abril 2025 -
 AlphaZero from Scratch – Machine Learning Tutorial14 abril 2025
AlphaZero from Scratch – Machine Learning Tutorial14 abril 2025 -
 Even AlphaZero Found This Game Hard14 abril 2025
Even AlphaZero Found This Game Hard14 abril 2025 -
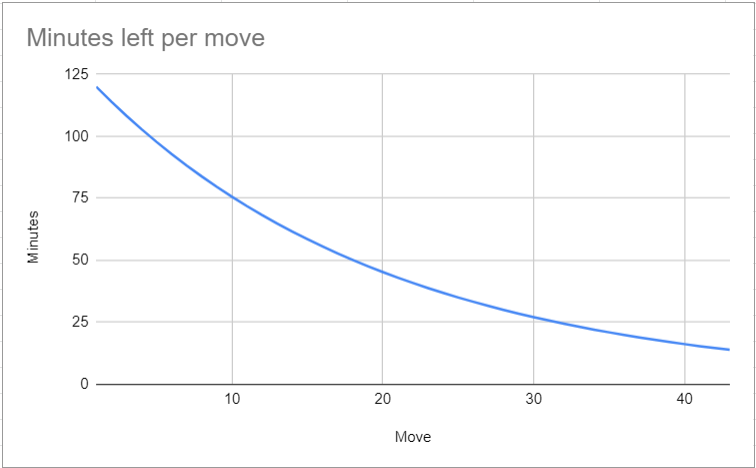 Time manager Alphazero - Leela Chess Zero14 abril 2025
Time manager Alphazero - Leela Chess Zero14 abril 2025 -
 最强通用棋类AI,AlphaZero强化学习算法解读- 深度强化学习实验室14 abril 2025
最强通用棋类AI,AlphaZero强化学习算法解读- 深度强化学习实验室14 abril 2025 -
GitHub - gemasphi/alpha-zero-torch: a clean generic alpha zero14 abril 2025
-
 Train on Small, Play the Large: Scaling Up Board Games with14 abril 2025
Train on Small, Play the Large: Scaling Up Board Games with14 abril 2025 -
![ANN] Announcing AlphaZero.jl - Package Announcements - Julia](https://global.discourse-cdn.com/julialang/original/3X/d/6/d63ab9eb4e8d7d6fa01287203f84057aef70b915.png) ANN] Announcing AlphaZero.jl - Package Announcements - Julia14 abril 2025
ANN] Announcing AlphaZero.jl - Package Announcements - Julia14 abril 2025 -
 xidong feng (@Xidong_Feng) / X14 abril 2025
xidong feng (@Xidong_Feng) / X14 abril 2025 -
GitHub - grimmer0125/alphago-zero-tictactoe-js: A game framework14 abril 2025
você pode gostar
-
 Veja as notas que Final Fantasy VII Remake vem recebendo14 abril 2025
Veja as notas que Final Fantasy VII Remake vem recebendo14 abril 2025 -
 Naruto shippuden temporada 3, Wiki14 abril 2025
Naruto shippuden temporada 3, Wiki14 abril 2025 -
 Spending the whole game as a bush (Zombs Royale.io) : Blizzard Playzz : Free Download, Borrow, and Streaming : Internet Archive14 abril 2025
Spending the whole game as a bush (Zombs Royale.io) : Blizzard Playzz : Free Download, Borrow, and Streaming : Internet Archive14 abril 2025 -
 Roblox Project Slayers, Different Items✓Trusted Seller✓14 abril 2025
Roblox Project Slayers, Different Items✓Trusted Seller✓14 abril 2025 -
 Free Download Garten of Banban Stinger Flynn Coloring Page in 2023 Coloring pages, Animal coloring pages, Kindergarten coloring pages14 abril 2025
Free Download Garten of Banban Stinger Flynn Coloring Page in 2023 Coloring pages, Animal coloring pages, Kindergarten coloring pages14 abril 2025 -
 Confirmado: João Félix é o jogador mais mal pago do Barcelona14 abril 2025
Confirmado: João Félix é o jogador mais mal pago do Barcelona14 abril 2025 -
 Giant Killing, Sakai Yoshinori and Sera Kyohei14 abril 2025
Giant Killing, Sakai Yoshinori and Sera Kyohei14 abril 2025 -
 ur unfriendly neighbourhood alternate on Twitter14 abril 2025
ur unfriendly neighbourhood alternate on Twitter14 abril 2025 -
 Killing Stalking - Manhwa – Harumio14 abril 2025
Killing Stalking - Manhwa – Harumio14 abril 2025 -
 Serviços por assinatura compensam mais do que comprar um jogo novo14 abril 2025
Serviços por assinatura compensam mais do que comprar um jogo novo14 abril 2025